CARC infrastructure
Many CARC users are new to the world of HPC and the machines at CARC are the first supercomputers they have ever used. As a result, it is not uncommon for them to be confused about what exactly a supercomputer is, how it is used and importantly, and what its strengths and limitations are. The goal of this document is to provide some information about the machines that CARC maintains, as well as how they are organized within the center, in the hopes that this will dispel some of the confusion users have.
CARC currently maintains and supports a number of named supercomputers, ie “Easley” or “Xena”, onto which many users login to each day, transfer data to and from, submit batch computational jobs to run in the background, analyze the results when they are done. The following summarizes CARC’s current production systems and their core specifications:
Easley (Mixed CPU/GPU Cluster)
• 65 compute nodes
• 4,160 total CPU cores
• 23.3 TB total RAM
• 36 NVIDIA L40s GPUs
• 8 NVIDIA H100 GPUs
• NVIDIA NDR 800 Gbps InfiniBand network
Hopper (GPU-Accelerated Cluster)
• 61 compute nodes
• 2,176 CPU cores
• 37 NVIDIA A100 GPUs
• NVIDIA HDR 400 Gbps InfiniBand network
Xena (GPU Cluster)
• 32 compute nodes
• 720 CPU cores
• NVIDIA K40 GPUs
• FDR 56 Gbps InfiniBand network
Each supercomputer, also known as a “cluster,” is made up of some number of individual computers, each not much different from the typical desktop PC we are all familiar with, except these computers, usually called “nodes,” are designed to be stacked together into racks, have specialized high speed network connectivity, and tend to have more memory and CPU cores than in typical consumer PCs. These nodes, whose number can reach into the thousands, are organized into racks because in such a high density, they require the climate control features of a modern machine-room such as raised floors and “hot-aisle” containment systems to prevent the mixing of hot and cold air, and thereby improving cooling efficiency. Aside from these physical differences, the hardware is much the same as a PC. The main components of the individual nodes are:
CPU containing multiple logical cores
RAM (memory)
Storage (which could be inside the node or as a separate network attached RAID array or both)
Network card
Optional co-processors such as a GPU or the Intel Xeon-Phi
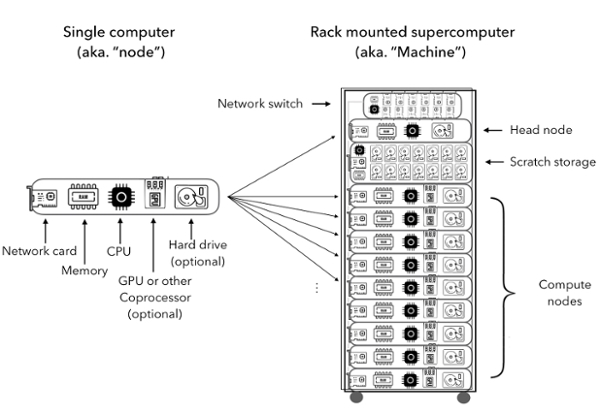
Figure 1. The main components of a single node and a cluster.
This is illustrated in Figure 1. Importantly, the CPUs used in supercomputers are not faster than those in your laptop or PC, and it is only by breaking up the computational problem up so that multiple cores within a CPU and/or multiple nodes within a machine are able to work on the problem simultaneously that these machines are able to solve the massive computational problems that are typically run at CARC.
There is a wide range in the ways that supercomputers can be configured, depending on the specific requirements but at CARC, and many other similar supercomputing centers around the world, they have the following components:One or two head (or login) node(s)
Tens or hundreds of compute nodes
High speed network switch
Storage array providing fast I/O scratch storage that can only be accessed within that machine
Most of these nodes are connected to each other via high-speed network and are called “compute nodes” as these are the workhorses of the center, and most work is performed by these nodes. Each machine also has at least one node which is defined as the “head” or “login” node because these nodes are the ones that are logged into and they run the queues to which jobs can be submitted before being sent out to the compute nodes to actually run.
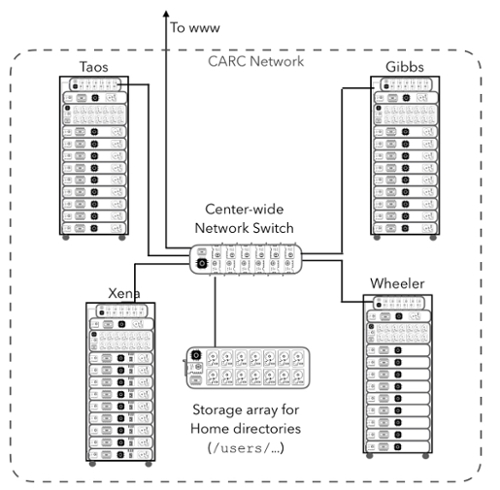
Figure 2. The CARC network, including clusters Xena, Wheeler, Taos and Gibbs, main network switch and the storage array containing home directories.
Figure 2 illustrates how the multiple machines CARC maintains are organized within the center itself, and how the home directories are not part of any particular machine, but rather a separate network attached storage node, that is then mounted on every compute and head node at the center. This has important consequences for where you perform calculations because if you have a job with high IO, you’ll want to minimize the distance from the storage device and the CPU doing the work. So a machine scratch or node hard drive are preferable to the home directories for high IO jobs. See the page about storage for more details.
